
Einzelhandel: Es geht ums Detail – im großen Stil
Ein Sprichwort besagt „Retail is detail at large scale.“ Es ist etwas Wahres dran: Um für reibungslose Betriebsabläufe und hohe Margen zu sorgen, müssen Einzelhändler den Überblick über Millionen von Warenflüssen pro Tag behalten. Im Zentrum dieser Fülle von Planungsaktivitäten steht die Absatzprognose.
Eine hochgradig exakte Absatzprognose ist die einzige Möglichkeit für Händler, vorherzusehen, welche Waren jeden Tag für jeden Standort und jeden Kanal benötigt werden. Nur so können sie ihren Kunden eine hohe Verfügbarkeit bieten und gleichzeitig Lagerkosten und Verderb geringhalten. Eine verlässliche Prognose, die über alle Betriebsprozesse hinweg eingesetzt wird, bietet weitere Vorteile: Sie unterstützt das Kapazitätsmanagement, stellt sicher, dass die richtige Anzahl an Mitarbeitern in den Filialen sowie Lagern eingesetzt wird und erleichtert Einkäufern, die Komplexität von Beschaffungen mit langer Vorlaufzeit zu bewältigen.
Unter stabilen Bedingungen ist das Generieren einer akkuraten Prognose simpel. Allerdings ist der Einzelhandel ein von Natur aus dynamisches Umfeld, in dem kontinuierlich Hunderte Faktoren die Nachfrage beeinflussen. Absatzplaner ringen deshalb jeden Tag damit, eine enorme Anzahl von Variablen zu berücksichtigen, darunter:
- Wiederkehrende Schwankungen des Basisabsatzes, wie etwa Wochentags- und saisonale Schwankungen.
- Interne Geschäftsentscheidungen, die die Aufmerksamkeit der Shopper erregen sollen, um Wettbewerbsvorteile zu erreichen, wie zum Beispiel Promotions, Preisanpassungen oder Änderungen der Filialdisplays.
- Externe Faktoren wie beispielsweise lokale Events, das Wetter oder Veränderungen in der Umgebung der Filiale und der Wettbewerbssituation vor Ort.
Bei dieser Fülle von Daten kann kein menschlicher Planer die volle Bandbreite potenzieller Einflussfaktoren berücksichtigen. Hier kommt Machine-Learning ins Spiel: Es ermöglicht, die Auswirkungen der genannten Faktoren auf detaillierter Ebene einzubeziehen – filialspezifisch oder pro Fulfillment-Kanal. Dass viele Einzelhändler ihre Technologiestrategie anpassen und dabei auf Machine-Learning-basierte Absatzprognostizierung setzen, überrascht also nicht.
1. Was ist Machine-Learning und warum sollten Händler es nutzen?
Machine-Learning erlaubt Systemen, automatisch zu lernen und ihre Empfehlungen allein auf Grundlage von Daten zu verbessern – ohne zusätzliches Programmieren. Da Einzelhändler gewaltige Datenmengen generieren, macht sich die Technologie schnell bezahlt. Wird ein Machine-Learning-System mit Daten gefüttert – je mehr, desto besser – sucht es darin nach Mustern, die es in bessere Entscheidungen verwandelt.
Beim Berechnen der Absatzprognosen ermöglicht maschinelles Lernen das Einbinden eines breiten Spektrums von Faktoren und Beziehungen, die täglich die Nachfrage beeinflussen. Das ist von enormem Wert, da allein Wetterdaten bereits aus Hunderten verschiedener Faktoren bestehen, die sich potenziell auf die Nachfrage auswirken. Machine-Learning-Algorithmen generieren automatisch und nur durch Daten, mit denen Sie sie füttern, sich ständig weiter verbessernde Modelle – ob Daten aus Ihrem Geschäft oder aus externen Datenströmen. Der Hauptvorteil eines solchen Systems ist, dass es Datensätze in der im Handel erforderlichen Größenordnung und aus einer Vielzahl von Quellen verarbeitet – ohne menschliches Eingreifen.
Natürlich sind Machine-Learning-Algorithmen keine Neuheit – sie existieren seit Jahrzehnten. Allerdings hatten sie bisher nie Zugang zu derart hohen Datenvolumen und entsprechender Datenverarbeitungsleistung. In der Vergangenheit hatten Einzelhändler Schwierigkeiten, ihre Prognosen schnell zu aktualisieren. Heute ermöglicht ihnen Datenverarbeitung auf Spitzenniveau dank In-Memory-Technologie, Millionen von Prognosen innerhalb einer einzigen Minute zu berechnen.
2. Mit Machine-Learning die Herausforderungen von Absatzprognosen im Einzelhandel bewältigen
In der datenreichen Einzelhandelsumgebung ist Machine-Learning ein sehr leistungsstarkes Tool. Es sollte überall dort eingesetzt werden, wo durch Daten Änderungen in der Nachfrage antizipiert oder erklärt werden können. In manchen Fällen füllt es sogar Lücken bei fehlenden Daten.
Die folgenden Arten von Nachfragefaktoren kann Machine-Learning erfassen:

2.1 Wochentage, Saisonalität und andere wiederkehrende Absatzmuster
Zeitreihenmodelle sind ein bewährter Ansatz, um gute Prognosen für wiederkehrende Muster zu liefern – zum Beispiel bei Wochentagsschwankungen oder saisonalen Änderungen. Wir haben jedoch die Erfahrung gemacht, dass Machine-Learning-basierte Prognostizierung kontinuierlich einen Genauigkeitsgrad bietet, der mindestens auf dem Stand des Zeitreihenmodells liegt und dieses meistens sogar übertrifft. Während Zeitreihenmodelle einfach Muster aus der Vergangenheit auf die Nachfrage der Zukunft anwenden, geht Machine-Learning einen Schritt weiter und definiert die tatsächliche Beziehung zwischen den Variablen (wie zum Beispiel Wochentagen) und den damit verknüpften Absatzmustern.
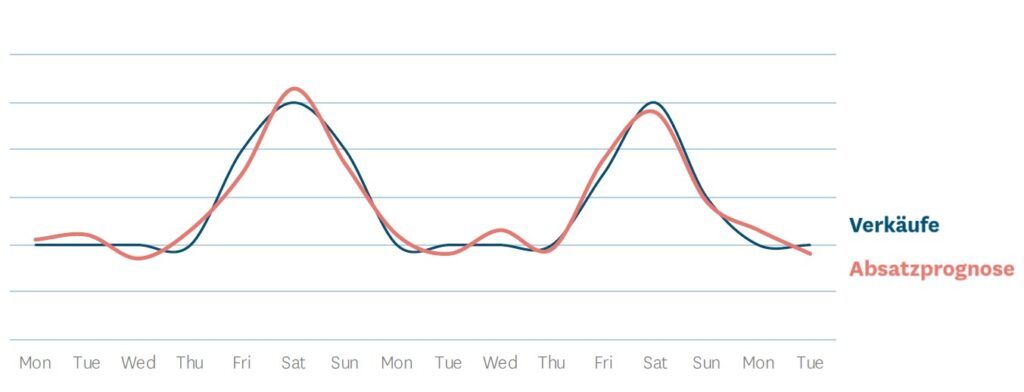
Machine-Learning optimiert und vereinfacht die Absatzprognostizierung im Einzelhandel. Werden Zeitreihenmodelle genutzt, müssen Händler die daraus hervorgehende Basisprognose so manipulieren, dass sie die Auswirkungen von beispielsweise Promotions und Preisänderungen berücksichtigt. Machine-Learning dagegen bezieht all diese Faktoren automatisch mit ein.
Maschinelles Lernen inkludiert nicht nur eine Fülle von Faktoren, sondern ermöglicht es auch, die Auswirkungen eines Zusammenspiels von mehreren Einflüssen zu erfassen – beispielsweise des Wetters und des Wochentags: Warmes, sonniges Wetter erhöht die Nachfrage nach Grillgut üblicherweise viel stärker, wenn es auf ein Wochenende fällt.
2.2 Preisänderungen, Promotions und andere Geschäftsentscheidungen mit Auswirkung auf die Nachfrage
Auch Ihre eigenen Geschäftsentscheidungen als Einzelhändler sind eine wichtige Ursache von Nachfrageschwankungen: von Promotions über Preisänderungen bis zu Anpassungen der Displays in Ihren Filialen. Doch obwohl Händler diese Änderungen selbst planen und kontrollieren, gelingt es vielen nicht, deren Wirkung genau vorherzusagen.
Mit Machine-Learning modellieren Händler akkurat die Preiselastizität eines Produkts – diese besagt, wie stark eine Preisänderung die Nachfrage des Produkts beeinflussen wird. Dies ist besonders für die Prognostizierung von Promotions wichtig. Aber auch bei der Optimierung von Markdown-Preisen ist Preiselastizität relevant: Nämlich, wenn Bestände vor einer Sortimentsänderung oder dem Ende einer Saison abverkauft werden sollen. Darüber hinaus müssen Händler regelmäßig die Verbraucherpreise anpassen, um die Lieferantenpreise und andere Änderungen ihrer Kostenbasis wiederzugeben.
Preiselastizität allein deckt die Auswirkung von Preisänderungen jedoch nicht voll ab. Die Preisgestaltung eines Produkts im Verhältnis zu alternativen Produkten innerhalb derselben Kategorie wirkt sich häufig ebenfalls stark aus. In vielen Kategorien entfällt ein unverhältnismäßig großer Anteil der Nachfrage auf das Produkt mit dem niedrigsten Preis. Machine-Learning-basierte Absatzprognosen liefern ein ziemlich eindeutiges Bild der Preisposition eines Produkts, wie in Abbildung 3 dargestellt.
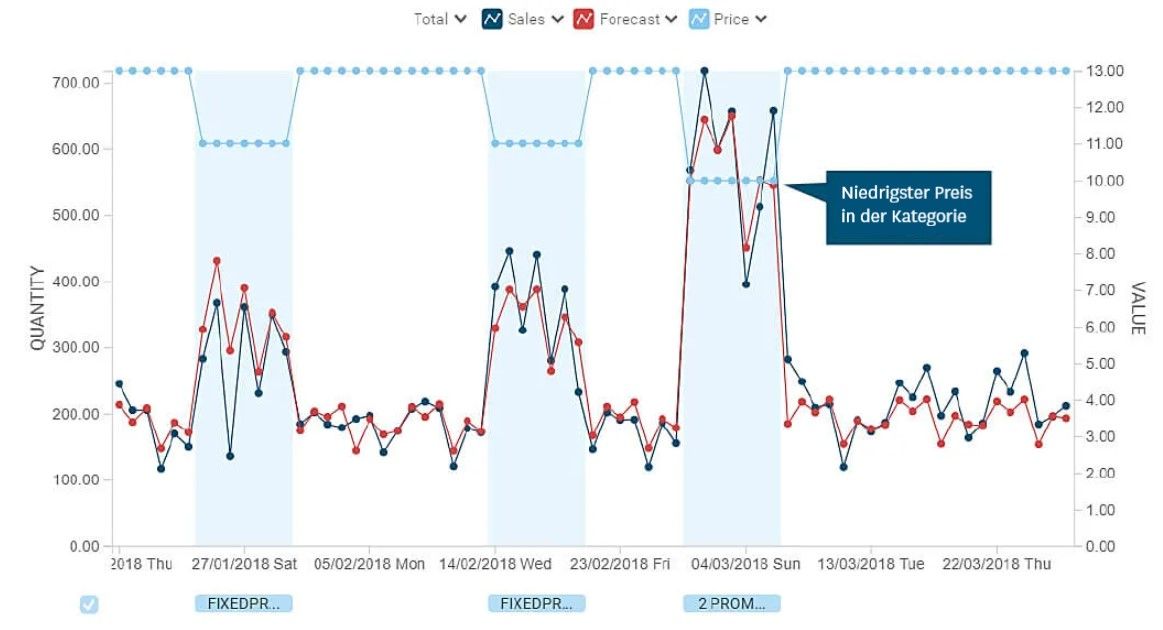
In einer 2020 veröffentlichten Studie nordamerikanischer Lebensmitteleinzelhändler gaben 70 Prozent der Befragten an, nicht alle relevanten Aspekte von Promotions – wie Preis, Kampagnentyp oder Filialdisplay – bei der Berechnung der kampagnenbedingten Prognoseerhöhungen miteinbeziehen zu können. Sie wünschten sich dies jedoch.
Auch hier ist maschinelles Lernen die Lösung. Absatzprognosen, die auf Machine-Learning basieren, ermöglichen es Händlern, den Einfluss von Promotions genau vorherzusagen. Dabei berücksichtigen sie die folgenden (und weitere) Faktoren:
- Kampagnentyp, wie zum Beispiel Preisreduktion oder Mengenrabatt
- Marketingaktivitäten, wie Prospekte oder Reklame in der Filiale
- Reduktionen des Produktpreises
- Filialdisplays, wie etwa die Präsentation des Kampagnenprodukts am Gondelkopf (Regalende) oder auf einem Tisch.
Die Kannibalisierung von Verkäufen bezeichnet eine kampagnenbedingte Absatzerhöhung eines Produkts, die sinkende Verkäufe anderer Produkte in der gleichen Kategorie nach sich zieht. Dieses häufige Phänomen muss in Prognosen bedacht werden, insbesondere für Frischeprodukte. Führt ein Supermarkt beispielsweise zwei Marken mit magerem Bio-Rinderhackfleisch – Weiderind und GrüneKuh –, ist davon auszugehen, dass eine Kampagne des Weiderind-Produkts dessen Absatz steigen lässt. Zudem ist es wahrscheinlich, dass ein Teil der Nachfrage nach dem GrüneKuh-Produkt sich zu Weiderind verlagern wird. Wird die Absatzprognose für das GrüneKuh-Produkt nicht entsprechend gesenkt, ist das Überbestandsrisiko und damit auch das für Verderb hoch.
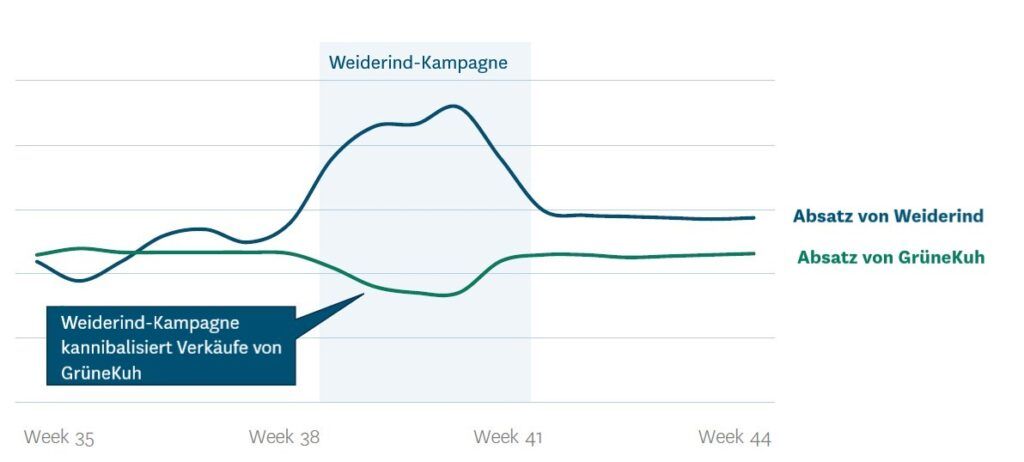
Im Einzelhandel ist es meist nicht möglich, die Prognosen für alle potenziell kannibalisierten Artikel manuell anzupassen – es sind schlicht zu viele. Üblicherweise sind die Muster sehr spezifisch für die Sortimente der einzelnen Filialen und das dortige Einkaufsverhalten. Die Fähigkeit von Machine-Learning-Algorithmen, Muster automatisch zu identifizieren und Prognosen entsprechend anzupassen, schafft hier enormen Mehrwert.
Eine Kampagne für das Weiderind-Produkt wird wahrscheinlich dazu führen, dass sich auch der Absatz einiger zu ihm in Bezug stehender Artikel außerhalb der Produktkategorie „Rinderhackfleisch“ erhöht: Der sogenannte Haloeffekt. Bei Hamburgerbrötchen ist dieser Zusammenhang mit Hackfleisch zum Beispiel recht offensichtlich und leicht vorhersehbar. Die Auswirkung der Kampagne kann im Sortiment jedoch so breit gestreut sein, dass es fast unmöglich wird, jedes betroffene Produkt zu identifizieren – selbst mit Hilfe von Machine-Learning. Denken Sie beispielsweise an Zwiebeln, Kartoffelchips, Bier, Wassermelone, Taco-Meal-Kits, Salatzubereitungen, Cracker, Maiskolben, Worcestershire-Sauce, Sojasauce oder alle möglichen anderen Artikel, die Shopper mit Hackfleischgerichten und beispielsweise einem Grillabend in Verbindung bringen. Doch auch wenn Prognosesysteme nicht jeden möglichen Haloeffekt identifizieren: Sie machen es den Disponenten leicht, Prognosen anzupassen und so weitere Beziehungen einzupflegen.
2.3 Wetter, lokale Events und andere externe Faktoren mit Auswirkung auf Verkäufe
Externe Faktoren wie Wetter, lokale Musik- und Sportveranstaltungen sowie Preisänderungen von Wettbewerbern können den Absatz stark beeinflussen. Ohne ein System, das einen Großteil der Arbeit automatisiert, sind diese Faktoren jedoch schwer in Prognosen zu berücksichtigen. Grob betrachtet lassen sich Wetterauswirkungen auf den Absatz intuitiv meist gut absehen: Steigende Temperaturen führen zu steigenden Speiseeisverkäufen während Niederschlag den Absatz von Regenschirmen ankurbelt etc.
Beim Blick auf das gesamte Sortiment eines Einzelhändlers wird die Sache jedoch komplizierter. Wie lassen sich alle Produkte, die auf das Wetter reagieren, effektiv identifizieren? Kann die gesamte Bandbreite von Variablen einer „Wettervorhersage“– also Temperatur, Sonnenschein, Regen und so weiter – einbezogen werden? Macht sich die Auswirkung von Sonnenschein im Sommer oder im Winter stärker bemerkbar? Ist sie an Wochenenden stärker als unter der Woche?
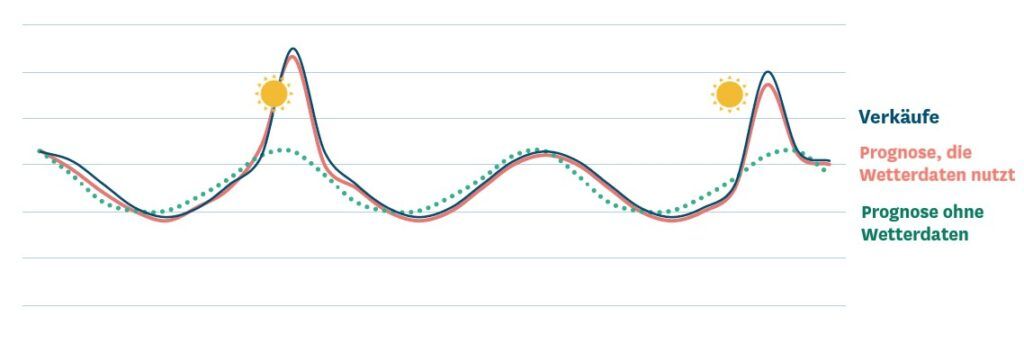
Das Verwenden von Wetterdaten in Absatzprognosen ist ein Paradebeispiel für die Leistungsfähigkeit von maschinellem Lernen. Machine-Learning-Algorithmen decken automatisch Beziehungen zwischen örtlichen Wettervariablen und lokalen Verkäufen auf. Daraufhin verorten sie diese Beziehungen viel granularer und genauer als ein Mensch dies jemals könnte. Zugleich identifizieren sie auch weniger offensichtliche Beziehungen, die der menschlichen Intuition oder dem „gesunden Menschenverstand“ entgehen könnten – und agieren dementsprechend.
Wenn Absatzplaner oder Filialmitarbeiter die Wettervorhersage manuell prüfen, um so Bestellentscheidungen anzupassen, konzentrieren sie sich darauf, den Nachschub für die antizipierten Absatzanstiege sicherzustellen – vor einer Hitzewelle pushen sie beispielsweise Eiscremebestände in die Filialen. Selten haben die Mitarbeiter jedoch Zeit, die Eiscremeprognosen leicht nach unten zu korrigieren, wenn sich im Sommer einige verregnete oder kältere Wochen einstellen. Planungsteams, die Machine-Learning einsetzen, müssen sich über solche Anpassungen keine Gedanken machen – sie erhalten die entsprechenden Vorschläge für Korrekturen automatisch von ihrem System.
Unserer Erfahrung nach führt die automatische Berücksichtigung von Wettereffekten in der Absatzprognostizierung auf Produktebene zu einer Reduktion der Prognosefehler um fünf bis 15 Prozent und auf Produktgruppen- und Filialebene um bis zu 40 Prozent.
Wetterdaten sind längst nicht die einzigen externen Daten, die Sie in Ihren Absatzprognosen miteinbeziehen können und sollten. Es lässt sich eine beliebige Anzahl externer Datenquellen heranziehen, um die Prognosegenauigkeit zu verbessern: So zum Beispiel vergangene und künftige lokale Veranstaltungen (wie Fußballspiele oder Konzerte), Preise von Wettbewerbern und Daten zur Mobilität der Kundschaft.
Mit Hilfe von Machine-Learning unterstützte RELEX beispielsweise WHSmith dabei, fundiertere Erkenntnisse über die Auswirkung der Flugpläne auf die Absatzmuster in den Filialen in Flughäfen zu gewinnen. Durch das Einspeisen externer Daten von Fluggesellschaften in das System verbesserte WHSmith seine Prognosen und reduzierte den Verderb von Frischwaren signifikant – gleichzeitig wurde die Verfügbarkeit bedeutsam erhöht.
2.4 Unbekannte Faktoren, die sich auf die Nachfrage auswirken
Bisher haben wir Kontexte betrachtet, in denen die nachfragebeeinflussenden Faktoren leicht zu identifizieren sind, wie etwa saisonale Muster, Geschäftsentscheidungen und andere externe Aspekte. Machine-Learning kann jedoch Prognosen selbst dann anpassen und präzisieren, wenn die internen oder externen Einflussfaktoren unbekannt sind.
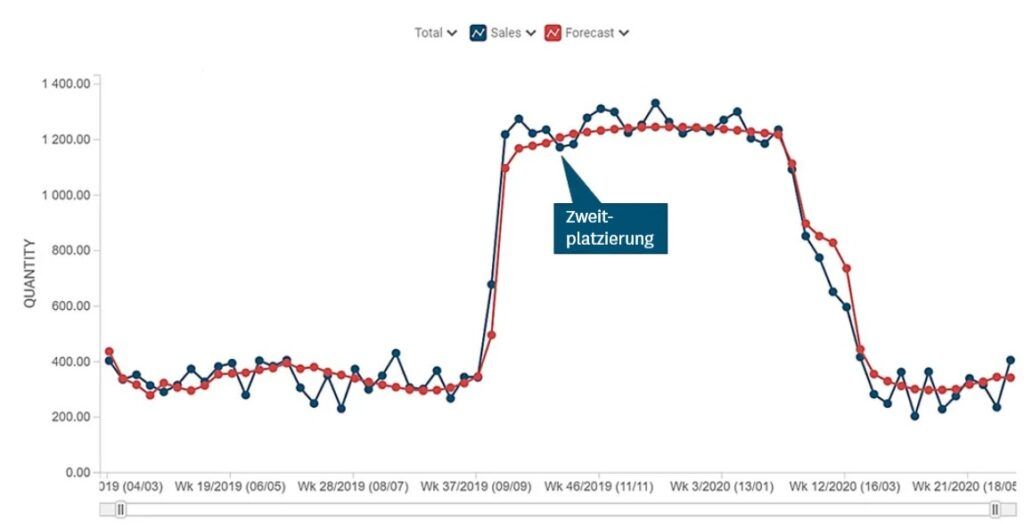
Im stationären Einzelhandel können Veränderungen der Umgebung, wie etwa die Filialeröffnung oder -schließung eines direkten Wettbewerbers in der Nachbarschaft, zu einer Veränderung der Nachfrage führen. Leider zeichnet nicht jedes System Daten über den Grund dieser Änderung auf. Selbst interne Geschäftsentscheidungen des Händlers, wie etwa die Zweitplatzierung eines Produkts, werden bisweilen nicht erfasst.
Auch hier bietet Machine-Learning Abhilfe. Die Algorithmen fügen dem Prognosemodell probeweise einen Strukturbruch (Changepoint) hinzu und beobachten die darauffolgenden Daten, um die Hypothese zu widerlegen oder zu validieren. So können sich Prognosen schnell und automatisch auf ein neues Absatzniveau einstellen.
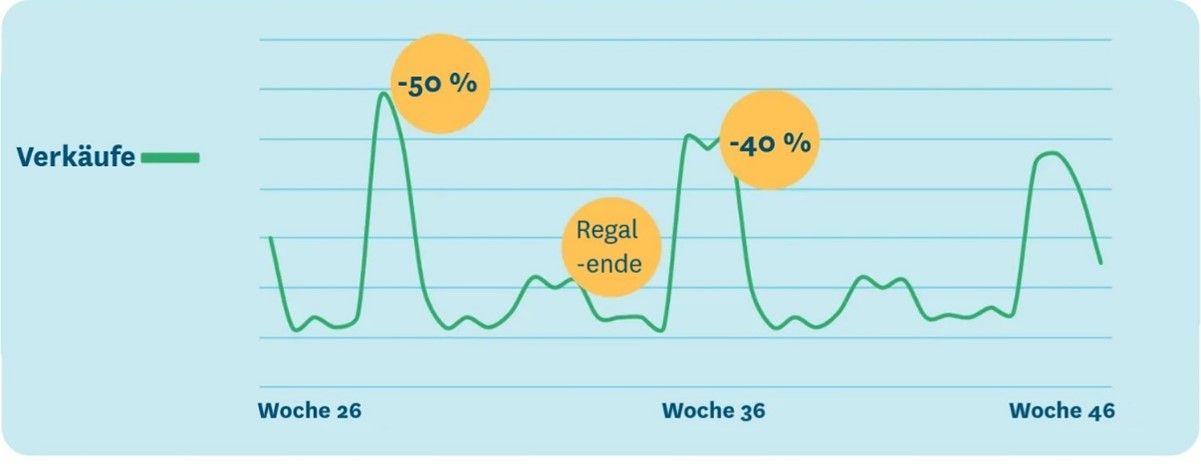
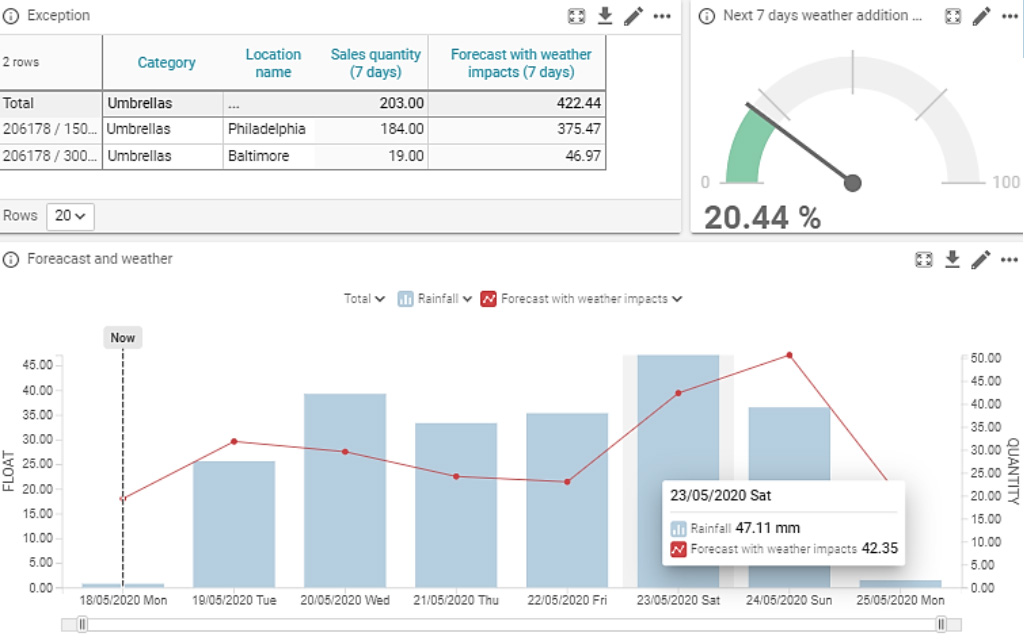
Im untenstehenden Beispiel in Abbildung 7 sehen Sie, dass zusätzlich zur normalen Regalfläche eines Produkts eine Zweitplatzierung erfolgte. Obwohl diese Änderung in den Stammdaten nicht aufgezeichnet wurde, führte das System die Absatzänderung auf das veränderte Filialdisplay zurück.
3. So setzen Sie Machine-Learning erfolgreich für Ihre Handelsplanung ein
Machine-Learning wird immer mehr zum Mainstream. Dennoch sollten Händler, die überlegen, wie sie die Technologie in ihrem Unternehmen einsetzen wollen, einige Aspekte bedenken. Manche dieser Überlegungen sind handelsspezifisch, andere wiederum – wie der Grad an Transparenz – sind so allgemein, dass sie sich auf jede Situation anwenden lassen, in der Teamwork von Mensch und Maschine gefragt ist.
3.1 Umgang mit Langsamdrehern
Eine handelsspezifische Herausforderung besteht darin, dass trotz der enormen, im Einzelhandel verfügbaren Datenmenge häufig nur wenige Daten pro Produkt, Filiale/Kanal und nachfragebeeinflussendem Faktor vorliegen. Selbst wenn die Jahresumsätze in die Milliarden gehen, verteilt sich das Gesamtvolumen auf mehrere Millionen Bestandsflüsse und Hunderte Tage.
Die Verkäufe sogenannter Langsamdreher – Produkte, von denen nur wenige Einheiten pro Tag oder Woche verkauft werden – sind meist zufälligen Schwankungen unterlegen. Das erschwert die verlässliche Identifikation von Beziehungsmustern im Datenrauschen. Mit nur wenigen verfügbaren Datenpunkten (im zwei- oder drei- statt vierstelligen Bereich) ist es eine Herausforderung, die Auswirkungen von nachfragebeeinflussenden Faktoren wie Wetter, Preis- und Displayänderungen oder Wettbewerbsaktivitäten von zufälligen Schwankungen zu unterscheiden.
Wenn Artikel mit geringen Absatzzahlen ein hohes Maß an Zufallsschwankungen enthalten, entsteht das Risiko einer „Überanpassung“, bei der der Algorithmus zu komplex wird oder zu viele Variablen enthält. Kommt es zur Überanpassung, prägt sich der Algorithmus das Datenrauschen ein, statt das tatsächliche, zugrundeliegende Nachfragemuster aufzugreifen. Ein solches Modell würde auf Grundlage des Rauschens prognostizieren. Mit den im Training verwendeten Daten kann das überangepasste Modell unter Umständen sehr gut performen. Werden jedoch neue, noch ungesehene Daten einbezogen, ist die Leistung mangelhaft. Typischerweise führt eine Überanpassung zu Prognosen, die gelegentlich deutlich aus der Reihe tanzen oder nervös sind – also zu stark auf geringe Veränderungen in den Daten reagieren.
Darüber hinaus ist es nicht immer möglich, saisonale Muster für Langsamdreher auf der Produktfilialebene aufzudecken: Eine Analyse der Verkäufe des Produkts auf Ebene der gesamten Lieferkette identifiziert hier leichter ein klares Muster. Dieses muss in der Disposition der Verteilzentren berücksichtigt werden.
Aufgrund des geringen Volumens und der spärlichen Datenlage auf Produkt-Filial-/Kanalebene im Einzelhandel sind folgende Punkte besonders wichtig:
Die Machine-Learning-Algorithmen müssen
- robust genug sein, keine Ausreißerergebnisse auf Grundlage ungenügender Datenpunkte zu liefern.
- eine Überanpassung vermeiden, indem sie Faktoren, die keine oder fast keine Auswirkung auf die Nachfrage haben, minimieren oder vereinfachen.
- sich nicht nur auf Produkt-Filial-/Kanalebene anwenden lassen, sondern auch auf verschiedenen Aggregationsebenen (z. B. Produktregion oder Produktkette) und in flexiblen Gruppierungen.
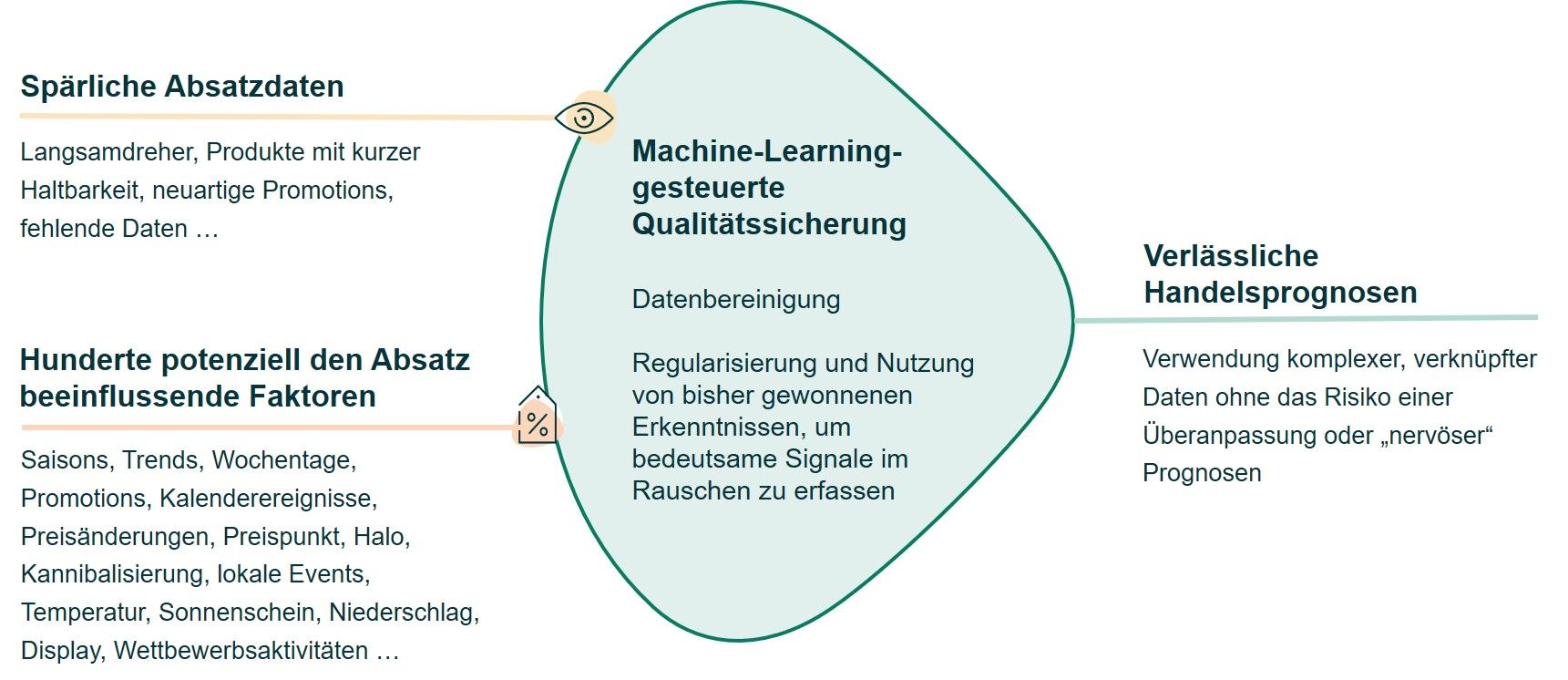
Abbildung 8: Um Überanpassung bei der Anwendung von Machine-Learning auf eine geringe Menge von Verkaufsdaten im Handel zu vermeiden, muss das System in der Lage sein, erstens zu vereinfachen, indem es Faktoren, die die Nachfrage kaum beeinflussen, reduziert, und zweitens Eingaben von Fachexperten erlauben, um relevante Beziehungen effektiver zu erkennen.
3.2 Menschliche Expertise effektiv einsetzen
Die COVID-19-Krise hat gezeigt, wie hilfreich automatisierte Prognostizierung und Disposition für Händler sind, die mit massiven Störungen konfrontiert werden: Automation nimmt den Disponenten viel Arbeit ab, was ihnen Zeit für andere Aufgaben verschafft. Diese Planungsexperten werden weiterhin benötigt, um das System bei der Bearbeitung neuer Vorgänge mit potenziell großen Auswirkungen anzuleiten. In solchen Situationen müssen Entscheidungen über eine gute Vorhersage hinausgehen – Händler müssen auch das Geschäftsrisiko von Best- und Worst-Case-Szenarien bewerten. Damit eine effektive Mensch-Computer-Kommunikation gelingt, egal ob in Ausnahmesituationen wie der Coronapandemie oder während Phasen mit normaler Nachfrage, benötigen Händler Analytik, die sich leicht in praktische Handlungsempfehlungen übersetzen lässt.
Da Prognosen niemals perfekt sind, wird es immer Situationen geben, in denen Planer eine Prognose zerlegen müssen. Je mehr Einsicht sie dabei in die bei der Prognose verwendeten Faktoren und deren Nutzung haben, desto stärker vertrauen sie dem System beim Managen von Routinesituationen. So können sie sich auf außergewöhnliche Situationen konzentrieren, die tatsächlich ihrer Aufmerksamkeit bedürfen. So genannte „Black-Box“-Systeme mit geringer Transparenz machen es aber unmöglich, zu verstehen, wie die automatisierten Empfehlungen zustande kommen. Benutzer gewinnen kein Vertrauen in solche Systeme, was häufig mit geringer Akzeptanz der Software einhergeht.
Eine transparente Lösung bietet Planern zudem wertvolle Erkenntnisse für zukünftige Verbesserungen – egal, ob es um hochwertigere Daten geht, die Notwendigkeit einer zusätzlichen Produktklassifizierung oder das Testen von neuen Faktorkombinationen (wie etwa das Hinzufügen einer Variable für den niedrigsten Preis im bereits erwähnten Ausreißerbeispiel).
3.3 Absatzprognosen sind nur EIN Teil der Handelsplanung und -optimierung
Absatzprognosen im Einzelhandel sind zwar essenziell, aber selbst die besten Prognosen sind wertlos, wenn sie Geschäftsentscheidungen nicht auf intelligente Weise unterstützen. Beim Managen von Langsamdrehern beispielsweise spielt Prognosegenauigkeit eine viel geringere Rolle für die Profitabilität als die Optimierung von Disposition und Flächenplanung. Die beiden letzteren sorgen für ausgeglichene Warenflüsse mit geringem Bedarf an manuellen Eingriffen entlang der Supply-Chain. Vorreiter im Einzelhandel wenden KI auf alle ihre Kernprozesse in der Handelsplanung an – Absatz, Betriebsprozesse und Merchandising – und fördern so Profitabilität und Nachhaltigkeit.
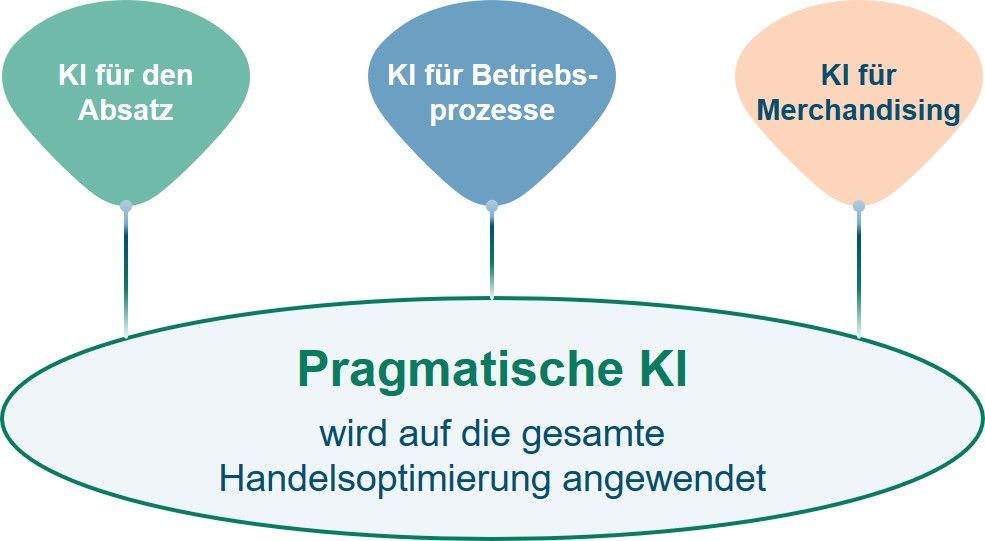
Abbildung 10: Absatzprognosen sind nur eines der Anwendungsgebiete für KI im Einzelhandel. Zukunftsorientierte Händler wenden KI auch auf Merchandising und Betriebsprozesse an und verbessern dadurch Profitabilität und Nachhaltigkeit.
Die Implementierung von Machine-Learning-basierten Absatzprognosen bietet eine stabile Grundlage, wenn Sie angewandte KI in Ihre Geschäftsprozesse einführen möchten. Doch das sollte nur der erste Schritt sein. Künstliche Intelligenz hat ihren Nutzen bereits bei der Bewältigung vielseitiger Herausforderungen in der Handelsplanung bewiesen: Von optimiertem Workforce-Management über effektiveren Güterumschlag in der Filiale bis zu hochgradig automatisierter und wirksamer Markdown-Optimierung. Wird pragmatische KI auf alle Kernprozesse im Einzelhandel angewendet, bietet sich eine Vielzahl von überraschend simplen und schnell erreichbaren Erfolgen.
Beitrag von




