Spezialisierung: Tuning für Ihre Datenverarbeitung
Aug 9, 2018 • 9 min
Wer Leistungsgrenzen ausreizen will, kommt an Spezialisierung nicht vorbei. Ein anschauliches Beispiel bietet hier der Motorsport: Das NASCAR-Rennen wird kein gewöhnlicher Pkw gewinnen – auch nicht, wenn er über einen besonders starken und teuren Motor verfügt. Der Motor eines NASCAR-Autos unterscheidet sich dabei gar nicht so sehr von dem eines normalen Wagens. Der V8-Motor ist etwa viermal leistungsstärker als die meisten Pkw-Vierzylindermotoren. Ein weiterer wichtiger Unterschied ist jedoch die Nockenwelle des Motors:
Die Nockenwelle reguliert die Menge des Luft-Kraftstoffgemischs, das der Motor ansaugt und als Abgase wieder ausstößt. Das wiederum gibt vor, wieviel Leistung der Motor erzeugt. In einem Rennwagen hält die Nockenwelle die Ansaugventile länger offen, um einen zusätzlichen Luftstrom zu erzeugen und Spitzen-Motorleistungen zu erreichen. Ein normaler Pkw hingegen würde mit diesem Prinzip beim im Straßenverkehr üblichen unteren bis mittleren Drehzahlbereich nicht rund laufen.
Um diese Stärke in Höchstgeschwindigkeit umzusetzen, werden Rennwagen vielseitig optimiert: hinsichtlich Aerodynamik und Anpressdruck, Gewicht und Robustheit sowie Gewichtsverteilung. Die entscheidenden Unterschiede zwischen dem Wagen in Ihrer Auffahrt und einem NASCAR-Rennauto lassen sich also unter dem Begriff Spezialisierung zusammenfassen.
Das Gleiche gilt auch für die Datenverarbeitung. Wollen Sie hier neue Spitzenleistungen erreichen, so ist Spezialisierung der entscheidende Vorteil, um das Rennen zu gewinnen.
Die Leistungsgrenzen der Datenverarbeitung erweitern
Bei datenlastigen Anwendungen wie Handelsplanung oder Analytics-Software überrascht, dass die Berechnungen selbst meist nicht den Leistungsengpass darstellen.
Häufiger hängt die Performance von zwei Faktoren ab: Wie schnell werden Daten im Speicher gefunden und von dort an den zentralen Prozessor (CPU) gesendet? Und wie effizient werden die Berechnungsergebnisse von der Datenbank an die Anwendungsschicht übertragen? Optimiert erzielen diese Bereiche Performance-Verbesserungen um mehrere Größenordnungen.
Superschnelle analytische Datenverarbeitung
Aus dem Arbeitsspeicher (RAM) lassen sich Daten 1.000-mal schneller als von der Festplatte abrufen. Somit überrascht es wenig, dass In-Memory-Computing (IMC) für datenintensive Anwendungen mittlerweile Standard ist. Dies ist insbesondere bei On-Demand-Analysen der Fall. Für gewöhnlich gehen spaltenorientierte Datenbanken mit In-Memory-Datenverarbeitung einher. Das hat vor allem zwei Gründe:
1. Effiziente Komprimierung ist für die In-Memory-Verarbeitung von großen Datenmengen ein Muss. Spaltenorientierte Datenbanken enthalten lange Sequenzen ähnlicher oder sich wiederholender Daten, die effizienter als in zeilenorientierten Datenbanken komprimiert werden können. Eine Spalte mit Handelsverkaufsdaten besteht für gewöhnlich aus vielen geringen Ganzzahlen und sich wiederholenden Nullen.
2. Der Datenabruf im Arbeitsspeicher erfordert immer noch Wartezeiten, diese sind jedoch wesentlich kürzer als beim Abruf von der Festplatte. Sequenzieller Zugriff ist deutlich schneller als der Datenabruf von verschiedenen physischen Speicherorten. Daher bieten spaltenorientierte Datenbanken überragende Leistung, wenn es darum geht, viele Daten in einer begrenzten Anzahl von Spalten zusammen zu verarbeiten. In der Handelsplanung und -analyse ist das häufig der Fall. Beispielsweise werden mehrere Jahre bereinigter Verkaufs- und Wetterdaten pro Filiale, Produkt und Tag benötigt, um den Einfluss des prognostizierten Wetters auf den Absatz zu bestimmen.
Datenkomprimierung ist eine Wissenschaft für sich, auf die hier nicht weiter eingegangen werden soll. Doch dieses Beispiel hilft, den Effekt scheinbar unverfänglicher technischer Entscheidungen zu veranschaulichen: Traditionelle Indexierungsverfahren zur schnelleren Auffindung von Daten können in Indextabellen resultieren, die um ein Tausendfaches größer sind als die eigentliche, komprimierte Datenbank. Diese Hürde lässt sich mit intelligentem Engineering überwinden, wie etwa dem Einsatz dünnbesetzter Indexstrukturen für sortierte Daten.
Die Datenbank erledigt die Schwerstarbeit
Zurück zur Rennwagen-Metapher: Spaltenorientierte Datenbanken, eine effektive Komprimierung und In-Memory-Datenverarbeitung bilden das Pendant zum V8-Motor des Rennautos. Damit Sie das Rennen gewinnen, braucht es jedoch mehr als einen kraftvollen Motor.
Eine Hochleistungsdatenbank allein reicht nicht aus, sie muss auch effektiv eingesetzt werden. Das erfordert eine optimierte Arbeitsteilung zwischen der Anwendung und der zugrundeliegenden Datenbank.
Es gilt, kostspielige Datentransfers zwischen der Anwendung und der Datenbank zu minimieren. Die verbleibenden notwendigen Datentransfers sollten dabei so effizient wie möglich gestaltet werden:
1. Teure Datenbewegungen lassen sich minimieren, indem datenlastige Berechnungen in der Datenbank nahe an den Rohdaten ausgeführt werden. Sind die Daten stark komprimiert, sollte zusätzlich darauf geachtet werden, niemals unkomprimierte Daten zu speichern, auch nicht zeitweise.
Ein grundlegendes Tool für datenintensive Berechnungen in der Datenbank ist die Database-Engine. Versteht sie die wichtigsten und häufigsten Datenstrukturen, die spezifisch für einen bestimmten Bereich sind, lassen sich datenintensive Berechnungen dieser Strukturen in der Datenbank durchführen. Dabei werden nur die Ergebnisse der Kalkulationen an die Anwendung zurückgegeben. So wird eine höhere Performance erreicht als beim Transfer großer Mengen von Rohdaten an die Anwendung zur dortigen Verarbeitung. Einige allgegenwärtige Konzepte zur Handelsplanung und -analyse sind für Standard-Datenbanken typischerweise schwer zu bewältigen, so zum Beispiel Kampagnen, Beziehungen zwischen Supply-Chain-Ebenen oder Referenz- und Ersatzprodukte.
2. Auch wenn datenintensive Berechnungen in der Datenbank durchgeführt werden, verbleibt ein Transferbedarf für Daten zwischen Anwendung und Datenbank. Ein eingebettetes Datenbankdesign maximiert den Durchsatz zwischen beiden. Da Anwendung und Datenbank sehr eng integriert sind und denselben physischen Speicherplatz verwenden, entsteht kein Mehraufwand durch (De-)Serialisierung, d.h. durch Übersetzung der Daten zwischen Speicher- und Transferformaten.
Es gilt, zwei Prinzipien zu beachten, um eine hohe Leistung datenlastiger Anwendungen zu erreichen: Berechnungen an Daten zu senden statt Daten an Berechnungen und eingebettete statt externe Datenbanken zu nutzen. Dies gilt insbesondere, wenn On-Demand-Analysen benötigt werden. Diese beiden Grundsätze behalten ihre Gültigkeit, unabhängig davon, ob mit einem einzigen Server oder einer dezentralen EDV-Architektur gearbeitet wird.
Um auf das NASCAR-Beispiel zurückzukommen: Die Database-Engine und die allgemeine Integration zwischen Anwendung und Datenbankschichten sind das Äquivalent zur Nockenwelle. Sie erlauben, alles aus der Hochleistungsdatenbank herauszuholen.

Leistungsanforderungen richtig ausbalancieren
Komprimierte, spaltenorientierte Datenbanken bieten überlegene Leistung bei Datenabfragen. Bei der Verarbeitung von Echtzeit-Transaktionen sind sie jedoch nicht so schnell wie zeilenorientierte, unkomprimierte Datenbanken. Dafür gibt es zwei Gründe: Werden Daten in einer komprimierten Datenbank aktualisiert, muss zumindest ein Teil der Daten erneut komprimiert werden, was einen Mehraufwand bedeutet. Darüber hinaus erlaubt ein zeilenorientierter Speicher schnelleres Einsetzen und Aktualisieren von Transaktionen, da jede auf einer Zeile (d.h. in sequenziellem Speicher) in der Datenbank gespeichert wird, statt in vielen Spalten (d.h. in vielen verschiedenen Speicherorten) in einer spaltenorientierten Datenbank.
In der Handelsplanung und -analyse entstehen die größten Leistungsanforderungen aus datenintensiven Abfragen, zum Beispiel beim Vergleich historischer Kampagnenerhöhungen für verschiedene Filialen, Kampagnentypen und Produktkategorien. Deshalb ist die In-Memory-Datenverarbeitung, die durch spaltenorientierte, komprimierte Datenbanken ermöglicht wird, zwar der Schlüssel zu außergewöhnlicher Performance – jedoch kann Datenverarbeitung nicht ausschließlich unter dem Gesichtspunkt der Analyse optimiert werden. Dateneingaben und aktualisierungen müssen genauso effizient gehandhabt werden.
Daraus ging hervor, was das Forschungs- und Beratungsunternehmen Gartner „Hybrid Transactional/Analytical Processing“ (HTAP) nennt: Dieselbe Datenplattform leistet sowohl „Online Transactional Processing“ (OLTP) als auch „Online Analytical Processing“ (OLAP), ohne dass Datenduplizierung nötig wird.
Es gibt mehrere Möglichkeiten, Daten effizient zu aktualisieren, ohne die Analyseleistung einer spaltenorientierten, komprimierten Datenbank zu drosseln. Zwei wichtige Ansätze sind die folgenden:
1. Das Bündeln von Aktualisierungen in Päckchen, um wiederholte Komprimierung für dieselben Datenblöcke zu minimieren: Paketverarbeitungen von Daten werden oft mit nächtlichen Update-Läufen gleichgesetzt. Diese sind, wenn machbar, eine gute Option. Paketverarbeitung kann jedoch auch beinahe in Echtzeit erfolgen. Das ein- oder mehrmalige Aktualisieren einer Datenbank pro Minute mit den neuesten Geschäftsvorgängen verbessert die Performance um Längen, verglichen mit der individuellen Verarbeitung jeder Transaktion.
2. Die Verwendung sowohl zeilenorientierter als auch spaltenorientierter Datenstrukturen, um von den Stärken beider zu profitieren: Neue oder aktualisierte Daten können zuerst in zeilenorientierten, sekundären Datenstrukturen gespeichert werden, um schnelle Updates und Einfügungen zu ermöglichen. Diese Daten stehen sofort für Abfragen zur Verfügung, obwohl die primären Datenbankstrukturen in Stapeln aktualisiert und neu komprimiert werden.
Ebenso wie ein NASCAR-Rennwagen Ihnen nicht das komfortabelste oder sparsamste Fahrerlebnis bietet, ist eine stark komprimierte spaltenorientierte Datenbank keine Wunderwaffe, die jede Herausforderung meistert. Es wird immer Situationen geben, in denen die maximale Leistung auf einem Gebiet zu einer unterdurchschnittlichen Leistung auf einem anderen führt. Beim optimalen Ausbalancieren dieser Austauschbeziehung erlangen Sie ein tiefgehendes Verständnis der wichtigsten Belange jedes Anwendungsfalls. Hier macht sich Spezialisierung also wirklich bezahlt.
Optimale Datenverarbeitung liefert echten Mehrwert
Dies war nur ein kurzer Blick darauf, wie Datenverarbeitung für bestimmte Zwecke optimiert werden kann. Sie ahnen, wie viel überlegt, entworfen und experimentiert werden muss, um eine Kombination aus schnellen On-Demand-Analysen, modernsten Berechnungen und hoher Verlässlichkeit für einen Einzelhändler liefern zu können, dessen tausende Filialen jeweils tausende Produkte führen, welche ständig neue Daten generieren.
Dennoch ist RELEX Solutions einer der wenigen Lösungsanbieter, der sich für die Entwicklung einer eigenen Datenbank und Database-Engine entschieden hat. Aus welchem Grund?
Unser Anspruch ist es, der weltbeste Anbieter von Handels- und Supply-Chain-Planungssoftware zu sein. Dazu braucht es eine außerordentliche Performance bei der Datenverarbeitung und spezialisierte Technologie.
Einige Beispiele zur Veranschaulichung:
Noch nie dagewesene Supply-Chain-Transparenz
Unsere besondere Rechenleistung ermöglicht vieles, das bisher nur sehr schwer oder gar nicht umsetzbar war.
Bei einem kürzlich durchgeführten Performance-Test berechneten wir Absatzprognosen auf Tagesebene für 100 Millionen SKUs 450 Tage im Voraus: Es wurden 45 Milliarden Prognosen in zwei Stunden und einer Minute erstellt. Große Einzelhändler müssen Daten in diesem Tempo verarbeiten: Nur so können sie ihre Dispositionspläne täglich aktualisieren und dabei von den neuesten Transaktions- und Planungsdaten sowie externen Daten wie Wetterprognosen profitieren.
Leistungsstarke Datenverarbeitung wird für das Aktualisieren von Prognosen benötigt. Noch wichtiger ist sie jedoch, um anhand dieser Prognosen weitere Berechnungen durchzuführen. Um proaktive Planung zu unterstützen, ermöglichen wir es unseren Kunden, routinemäßig jeden künftigen Status ihrer Supply-Chain auf SKU-Filial/Lager-Tag-Ebene abzubilden: So lässt sich ablesen, welche Bestellungen aufgegeben und geliefert werden, welche Mengen kommissioniert und transportiert werden müssen und so weiter. Unsere Planungslösung berechnet dies täglich, mehrere Monate oder sogar ein Jahr im Voraus – andere haben schon Probleme, Einsicht in die kommende Woche zu erlangen.
Dieser Weitblick lässt sich klar in Geschäftswert übertragen: optimierte Supply-Chain-Kapazitäten, die die Nachfrage wesentlich präziser abbilden.
Technisch ausgereifte Automatisierung
urch die volle Kontrolle über die Database-Engine konnten wir unsere eigene Abfragesprache entwickeln, die ganz auf die Handelsplanung und -analyse zugeschnitten ist. Mit ihr entwickeln die Planungsexperten unserer Kunden einfach ihre eigenen Abfragen einschließlich spezifischer Kennzahlen. So lassen sich alle Analysebedarfe flexibel erfüllen, ohne sich mit klobigem SQL abmühen zu müssen.
Dank unserer hauseigenen Abfragesprache haben wir auch eine grafische Benutzeroberfläche entwickelt, mit der die Prozessexperten unserer Kunden automatisierte Abfragen erstellen, die regelmäßig oder in Ausnahmesituationen ausgeführt werden. Diese automatischen Abfragen nennen wir Business Rules, jedoch lassen sie sich auch als integrierte „Robotic Process Automation“ (RPA) verstehen.
Unsere Kunden nutzen die Business Rules Engine im Allgemeinen, um
- Abläufe automatisch zu optimieren,
- das Ausnahmen-Management gemäß geschäftlichen Prioritäten zu automatisieren und
- automatische Routinen zur Verwaltung der Stammdaten zu erstellen.
Ein Beispiel automatischer Optimierung ist die virtuelle Zweckbindung, die benötigt wird, wenn Filialen und Onlinekanäle denselben Vorratspool nutzen. Ein Beispiel für die Verwaltung von Ausnahmen ist automatische Allokation bei Knappheit gemäß festgelegten Geschäftszielen – beispielsweise, um den Gesamtumsatz zu maximieren oder die Produktverfügbarkeit in Filialen mit geringer Sortimentsbreite zu priorisieren. Diese greift, wenn das System erkennt, dass künftige Filialbestellungen den projizierten verfügbaren Bestand überschreiten.
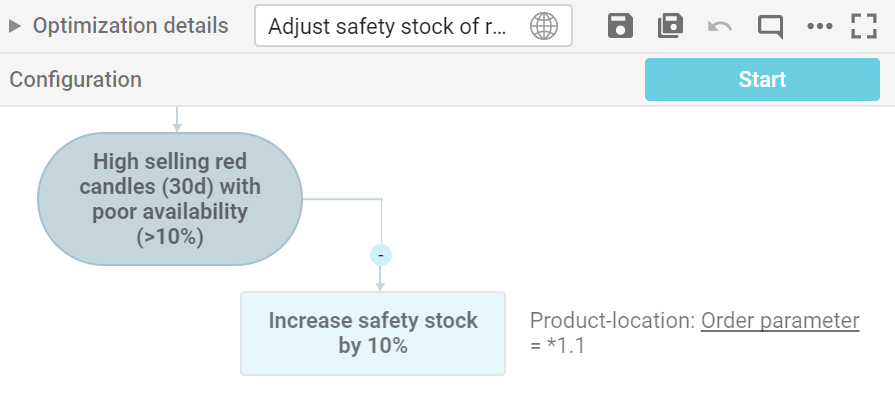

Große Einzelhändler können leicht dutzende oder sogar hunderte Geschäftsregeln verwenden, um die Steuerung verschiedener Produktkategorien, Filialtypen, Lieferanten, Ausnahmen etc. zu verfeinern und zu differenzieren.
Die Konfiguration der Geschäftsregeln erfolgt ohne Programmierung, sodass die Super-User des Kunden sie komplett selbst entwickeln können, ohne von IT-Ressourcen, Budgets oder RELEX als Lösungsanbieter abhängig zu sein. Zudem verkomplizieren die Konfigurationen nicht die Updates der Software.
Realistische Szenario-Planung
Unsere Technologie unterstützt mehrere parallele Arbeitskopien. Das macht detailliertes Planen von Szenarien einfacher als je zuvor.
Kurz gesagt, können Planer im Bedarfsfall unmittelbar eine vollständige Kopie ihrer aktuellen Produktionsumgebung aufrufen (einschließlich aller Daten, Parameter, individuellen Geschäftsregeln, etc.) und dort alle gewünschten Änderungen an Parametern vornehmen: zum Beispiel an Lieferplänen, Absatzprognosen oder der Terminierung bestimmter Lieferungen. Die Auswirkungen dieser Änderungen etwa auf Kapazitätsbedarfe können an jeder Stelle der Supply-Chain und in jeder Detailtiefe überprüft werden. Nutzer können mehrere Szenarien durchspielen und sie untereinander oder auch mit dem aktuellen Ist-Zustand vergleichen. Danach können sie sämtliche gewünschten Änderungen auf die Produktionsumgebung anwenden.
Diese Funktion ist essenziell für die Absatz- und Vertriebsplanung im Einzelhandel, in dem detaillierte Analysen der Auswirkungen auf einzelne Filialen, Lagerabschnitte oder Tage unverzichtbar sind, wenn beispielsweise die Hochsaison vorbereitet wird. Große Lebensmittelhändler sparen allein durch die präzisere Planung der Weihnachtssaison jedes Jahr Millionenbeträge ein.
Das Rennen geht in die nächste Runde
Das vergangene Jahrzehnt war geprägt durch enorme Leistungsfortschritte in der Datenverarbeitung. Nie dagewesene Datenmengen können verarbeitet und analysiert werden, doch nun stellt sich die Frage: Sind die Grenzen bald ausgereizt?
Die kurze Antwort auf diese Frage lautet: nein. Wir entdecken weiterhin großartige Wege, den Grad an Raffinesse und Automatisierung für Planungsprozesse zu steigern. Vielmehr noch bieten sich neue Möglichkeiten, verschiedene Planungsprozesse wie Supply-Chain, Merchandising und Personalplanung noch enger zu verknüpfen.
Wer stets das Rennen anführen will, benötigt jedoch ein Team von Ingenieuren, das ein tiefgehendes Verständnis für alle Komponenten der Lösung und deren Zusammenspiel besitzt: von der Hardware über die Software bis zu den Eigenschaften der Daten und den typischen Anwendungsfällen in einem spezifischen Bereich.
Um intelligente Technologie richtig einzusetzen, bedarf es also kluger Menschen.
Sources
Autotrader: NASCAR vs. Your Street Car: What’s the Difference?
Beitrag von

ähnliche Artikel

Lebensmittelhandel neu denken statt “wie immer”: Die 3 Schritte zur selbstfinanzierten Transformation
Entdecken Sie, wie der LEH das Zögern überwinden und schrittweise KI implementieren kann, um wettbewerbsfähig zu bleiben, Verkaufszahlen, Verkäufe und Kundenbindung zu steigern und Abfall zu reduzieren.

Frage und Antwort mit CEO Mikko Kärkkäinen: Skalierung von KI für verbraucherzentriertes Wachstum
Entdecken Sie bewährte Strategien zur Skalierung und Aufrechterhaltung von KI-Initiativen, mit Einblicken von Mikko Kärkkäinen, CEO von RELEX Solutions.

Q&A: Wie KI Promotions in Profit verwandelt
Erfahren Sie, wie RELEX AI Werbestrategien mit datengesteuerter, einheitlicher Planung umgestaltet, die profitable, kundenorientierte Ergebnisse liefert.